> For clean Markdown of any page, append .md to the page URL.
> For a complete documentation index, see https://docs.boundaryml.com/llms.txt.
> For AI client integration (Claude Code, Cursor, etc.), connect to the MCP server at https://docs.boundaryml.com/_mcp/server.
# Why BAML?
> The journey from simple LLM calls to production-ready structured extraction
Let's say you want to extract structured data from resumes. It starts simple enough...
But first, let's see where we're going with this story:
*BAML: What it is and how it helps - see the full developer experience*
## It starts simple
You begin with a basic LLM call to extract a name and skills:
```python
import openai
def extract_resume(text):
response = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Extract name and skills from: {text}"}]
)
return response.choices[0].message.content
```
This works... sometimes. But you need structured data, not free text.
## You need structure
So you try JSON mode and add Pydantic for validation:
```python
from pydantic import BaseModel
import json
class Resume(BaseModel):
name: str
skills: list[str]
def extract_resume(text):
prompt = f"""Extract resume data as JSON:
{text}
Return JSON with fields: name (string), skills (array of strings)"""
response = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}
)
data = json.loads(response.choices[0].message.content)
return Resume(**data)
```
Better! But now you need more fields. You add education, experience, and location:
```python
class Education(BaseModel):
school: str
degree: str
year: int
class Resume(BaseModel):
name: str
skills: list[str]
education: list[Education]
location: str
years_experience: int
```
The prompt gets longer and more complex. But wait - how do you test this without burning tokens?
## Testing becomes expensive
Every test costs money and takes time:
```python
# This burns tokens every time you run tests!
def test_resume_extraction():
test_resume = "John Doe, Python expert, MIT 2020..."
result = extract_resume(test_resume) # API call = $$$
assert result.name == "John Doe"
```
You try mocking, but then you're not testing your actual extraction logic. Your prompt could be completely broken and tests would still pass.
## Error handling nightmare
Real resumes break your extraction. The LLM returns malformed JSON:
```json
{
"name": "John Doe",
"skills": ["Python", "JavaScript"
// Missing closing bracket!
```
You add retry logic, JSON fixing, error handling:
```python
import re
import time
def extract_resume(text, max_retries=3):
for attempt in range(max_retries):
try:
response = openai.chat.completions.create(...)
content = response.choices[0].message.content
# Try to fix common JSON issues
content = fix_json(content)
data = json.loads(content)
return Resume(**data)
except (json.JSONDecodeError, ValidationError) as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # Exponential backoff
def fix_json(content):
# Remove text before/after JSON
json_match = re.search(r'\{.*\}', content, re.DOTALL)
if json_match:
content = json_match.group(0)
# Fix common issues
content = content.replace(',}', '}')
content = content.replace(',]', ']')
# ... more fixes
return content
```
Your simple extraction function is now 50+ lines of infrastructure code.
## Multi-model chaos
Your company wants to use Claude for some tasks (better reasoning) and GPT-4-mini for others (cost savings):
```python
def extract_resume(text, provider="openai", model="gpt-4o"):
if provider == "openai":
import openai
client = openai.OpenAI()
response = client.chat.completions.create(model=model, ...)
elif provider == "anthropic":
import anthropic
client = anthropic.Anthropic()
# Different API! Need to rewrite everything
response = client.messages.create(model=model, ...)
# ... handle different response formats
```
Each provider has different APIs, different response formats, different capabilities. Your code becomes a mess of if/else statements.
## The prompt mystery
Your extraction fails on certain resumes. You need to debug, but what was actually sent to the LLM?
```python
# What prompt was generated? How many tokens did it use?
# Why did this specific resume fail?
# How do I optimize for cost?
# You can't easily see:
# - The exact prompt that was sent
# - How the schema was formatted
# - Token usage breakdown
# - Why specific fields were missed
```
You start adding logging, token counting, prompt inspection tools...
## Classification gets complex
Now you need to classify seniority levels:
```python
from enum import Enum
class SeniorityLevel(str, Enum):
JUNIOR = "junior"
MID = "mid"
SENIOR = "senior"
STAFF = "staff"
class Resume(BaseModel):
name: str
skills: list[str]
education: list[Education]
seniority: SeniorityLevel
```
But the LLM doesn't know what these levels mean! You update the prompt:
```python
prompt = f"""Extract resume data as JSON:
Seniority levels:
- junior: 0-2 years experience
- mid: 2-5 years experience
- senior: 5-10 years experience
- staff: 10+ years experience
{text}
Return JSON with fields: name, skills, education, seniority..."""
```
Your prompt is getting huge and your business logic is scattered between code and strings.
## Production deployment headaches
In production, you need:
* Retry policies for rate limits
* Fallback models when primary is down
* Cost tracking and optimization
* Error monitoring and alerting
* A/B testing different prompts
Your simple extraction function becomes a complex service:
```python
class ResumeExtractor:
def __init__(self):
self.primary_client = openai.OpenAI()
self.fallback_client = anthropic.Anthropic()
self.token_tracker = TokenTracker()
self.error_monitor = ErrorMonitor()
async def extract_with_fallback(self, text):
try:
return await self._extract_openai(text)
except RateLimitError:
return await self._extract_anthropic(text)
except Exception as e:
self.error_monitor.log(e)
raise
def _extract_openai(self, text):
# 50+ lines of OpenAI-specific logic
pass
def _extract_anthropic(self, text):
# 50+ lines of Anthropic-specific logic
pass
```
## Enter BAML
What if you could go back to something simple, but keep all the power?
```baml
class Education {
school string
degree string
year int
}
enum SeniorityLevel {
JUNIOR @description("0-2 years of experience")
MID @description("2-5 years of experience")
SENIOR @description("5-10 years of experience")
STAFF @description("10+ years of experience, technical leadership")
}
class Resume {
name string
skills string[]
education Education[]
seniority SeniorityLevel
}
function ExtractResume(resume_text: string) -> Resume {
client GPT4
prompt #"
Extract information from this resume.
Resume:
---
{{ resume_text }}
---
{{ ctx.output_format }}
"#
}
```
Look what you get immediately:
*BAML playground showing successful resume extraction with clear prompts and structured output*
### 1. **Instant Testing**
Test in VSCode playground without API calls or token costs:
* **See the exact prompt** that will be sent to the LLM
* **Test with real data instantly** - no API calls needed
* **Save test cases** for regression testing
* **Visual prompt preview** shows token usage and formatting
*Build up a library of test cases that run instantly*
### 2. **Multi-Model Made Simple**
```baml
client GPT4 {
provider openai
options { model "gpt-4o" }
}
client Claude {
provider anthropic
options { model "claude-3-opus-20240229" }
}
client GPT4Mini {
provider openai
options { model "gpt-4o-mini" }
}
// Same function, any model - just change the client
function ExtractResume(resume_text: string) -> Resume {
client GPT4 // Switch to Claude or GPT4Mini with one line
prompt #"..."#
}
```
### 3. **Schema-Aligned Parsing (SAP)**
BAML's breakthrough innovation follows Postel's Law: *"Be conservative in what you do, be liberal in what you accept from others."*
Instead of rejecting imperfect outputs, SAP actively transforms them to match your schema using custom edit distance algorithms.
**SAP vs Other Approaches:**
| Model | Function Calling | Python AST Parser | **SAP** |
| -------------- | ---------------- | ----------------- | --------- |
| gpt-3.5-turbo | 87.5% | 75.8% | **92%** |
| gpt-4o | 87.4% | 82.1% | **93%** |
| claude-3-haiku | 57.3% | 82.6% | **91.7%** |
**Key insight:** SAP + GPT-3.5 turbo beats GPT-4o + structured outputs, saving you money while improving accuracy.
**What SAP fixes automatically:**
*Raw LLM Output:*
```json
// The model often outputs this mess:
{
"name": John Doe, // Missing quotes
"skills": ["Python", "JavaScript",], // Trailing comma
"experience": 3.5 years, // Invalid type
"bio": "I'm a \"developer\"", // Unescaped quotes
/* some comment */ // JSON comments
"confidence": 9/10 // Fraction instead of decimal
}
```
*SAP Transforms to:*
```json
{
"name": "John Doe",
"skills": ["Python", "JavaScript"],
"experience": 3.5,
"bio": "I'm a \"developer\"",
"confidence": 0.9
}
```
**Error correction techniques:**
* Adds missing quotes around strings
* Removes trailing commas
* Strips comments and "yapping"
* Converts fractions to decimals
* Escapes special characters
* Handles incomplete JSON sequences
**Traditional JSON Schema (verbose):**
```json
{
"type": "object",
"properties": {
"name": {
"type": "string",
"description": "The person's full name"
},
"skills": {
"type": "array",
"items": {"type": "string"},
"description": "List of technical skills"
},
"experience": {
"type": "number",
"description": "Years of experience"
}
},
"required": ["name", "skills"]
}
```
*Token count: \~180 tokens*
**BAML Schema (optimized):**
```baml
class Resume {
name string @description("The person's full name")
skills string[] @description("List of technical skills")
experience float? @description("Years of experience")
}
```
*Token count: \~35 tokens*
**80% token reduction** while being clearer to the model!
**Traditional approach** - Choose reasoning OR structure:
```python
# Either get reasoning (unstructured)
reasoning = llm.complete("Analyze this resume and explain your thinking...")
# OR get structure (no reasoning)
resume = llm.structured_output(resume_schema, text)
```
**BAML's SAP** - Get both in one call:
```baml
class ResumeAnalysis {
reasoning string @description("Step-by-step analysis")
name string
skills string[]
seniority_level SeniorityLevel
confidence_score float
}
function AnalyzeResume(text: string) -> ResumeAnalysis {
client GPT4
prompt #"
Analyze this resume step by step, then extract structured data.
Resume: {{ text }}
{{ ctx.output_format }}
"#
}
```
**Result:** Chain-of-thought reasoning AND structured output in a single API call.
### 4. **Production Features Built-In**
```baml
client RobustGPT4 {
provider openai
options { model "gpt-4o" }
retry_policy {
max_retries 3
strategy exponential_backoff
}
}
client SmartFallback {
provider fallback
options {
clients ["GPT4", "Claude", "GPT4Mini"]
}
}
```
### 5. **Token Optimization**
* See exact token usage for every call
* BAML's schema format uses 80% fewer tokens than JSON Schema
* Optimize prompts with instant feedback
### 6. **Type Safety Everywhere**
```python
from baml_client import baml as b
# Fully typed, works in Python, TypeScript, Java, Go
resume = await b.ExtractResume(resume_text)
print(resume.seniority) # Type: SeniorityLevel
```
*BAML generates fully typed clients for all languages automatically*
**See how changes instantly update the prompt:**
*Change your types → Prompt automatically updates → See the difference immediately*
### 7. **Advanced Streaming with UI Integration**
BAML's semantic streaming lets you build real UIs with loading bars and type-safe implementations:
```baml
class BlogPost {
title string @stream.done @stream.not_null
content string @stream.with_state
}
```
**What this enables:**
* **Loading bars** - Show progress as structured data streams in
* **Semantic guarantees** - Title only appears when complete, content streams token by token
* **Type-safe streaming** - Full TypeScript/Python types for partial data
* **UI state management** - Know exactly what's loading vs complete
*See semantic streaming in action - structured data streaming with loading states*
## The Bottom Line
**You started with:** A simple LLM call
**You ended up with:** Hundreds of lines of infrastructure code
**With BAML, you get:**
* The simplicity of your first attempt
* All the production features you built manually
* Better reliability than you could build yourself
* 10x faster development iteration
* Full control and transparency
BAML is what LLM development should have been from the start. Ready to see the difference? [Get started with BAML](/guide/installation-language/python).
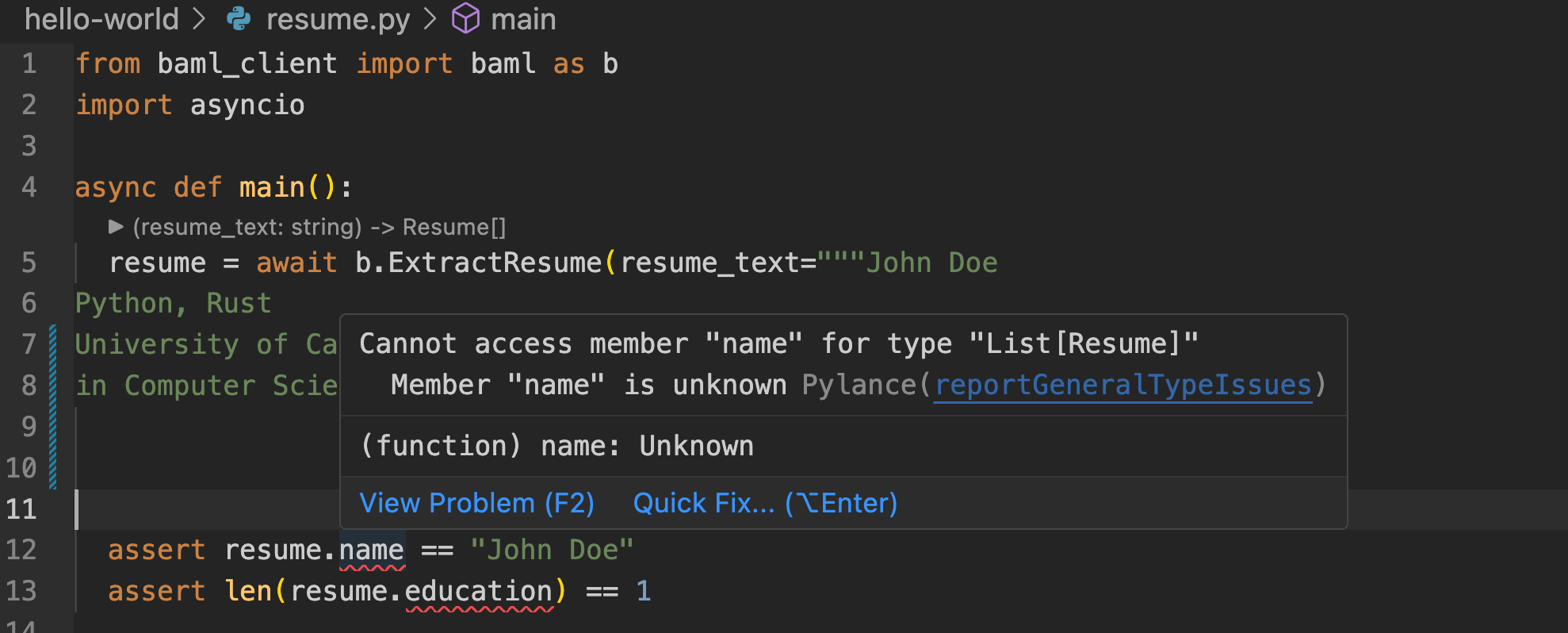 ```json
{
"name": "John Doe",
"skills": ["Python", "JavaScript"
// Missing closing bracket!
```
You add retry logic, JSON fixing, error handling:
```python
import re
import time
def extract_resume(text, max_retries=3):
for attempt in range(max_retries):
try:
response = openai.chat.completions.create(...)
content = response.choices[0].message.content
# Try to fix common JSON issues
content = fix_json(content)
data = json.loads(content)
return Resume(**data)
except (json.JSONDecodeError, ValidationError) as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # Exponential backoff
def fix_json(content):
# Remove text before/after JSON
json_match = re.search(r'\{.*\}', content, re.DOTALL)
if json_match:
content = json_match.group(0)
# Fix common issues
content = content.replace(',}', '}')
content = content.replace(',]', ']')
# ... more fixes
return content
```
Your simple extraction function is now 50+ lines of infrastructure code.
## Multi-model chaos
Your company wants to use Claude for some tasks (better reasoning) and GPT-4-mini for others (cost savings):
```python
def extract_resume(text, provider="openai", model="gpt-4o"):
if provider == "openai":
import openai
client = openai.OpenAI()
response = client.chat.completions.create(model=model, ...)
elif provider == "anthropic":
import anthropic
client = anthropic.Anthropic()
# Different API! Need to rewrite everything
response = client.messages.create(model=model, ...)
# ... handle different response formats
```
Each provider has different APIs, different response formats, different capabilities. Your code becomes a mess of if/else statements.
## The prompt mystery
Your extraction fails on certain resumes. You need to debug, but what was actually sent to the LLM?
```python
# What prompt was generated? How many tokens did it use?
# Why did this specific resume fail?
# How do I optimize for cost?
# You can't easily see:
# - The exact prompt that was sent
# - How the schema was formatted
# - Token usage breakdown
# - Why specific fields were missed
```
You start adding logging, token counting, prompt inspection tools...
## Classification gets complex
Now you need to classify seniority levels:
```python
from enum import Enum
class SeniorityLevel(str, Enum):
JUNIOR = "junior"
MID = "mid"
SENIOR = "senior"
STAFF = "staff"
class Resume(BaseModel):
name: str
skills: list[str]
education: list[Education]
seniority: SeniorityLevel
```
But the LLM doesn't know what these levels mean! You update the prompt:
```python
prompt = f"""Extract resume data as JSON:
Seniority levels:
- junior: 0-2 years experience
- mid: 2-5 years experience
- senior: 5-10 years experience
- staff: 10+ years experience
{text}
Return JSON with fields: name, skills, education, seniority..."""
```
Your prompt is getting huge and your business logic is scattered between code and strings.
## Production deployment headaches
In production, you need:
* Retry policies for rate limits
* Fallback models when primary is down
* Cost tracking and optimization
* Error monitoring and alerting
* A/B testing different prompts
Your simple extraction function becomes a complex service:
```python
class ResumeExtractor:
def __init__(self):
self.primary_client = openai.OpenAI()
self.fallback_client = anthropic.Anthropic()
self.token_tracker = TokenTracker()
self.error_monitor = ErrorMonitor()
async def extract_with_fallback(self, text):
try:
return await self._extract_openai(text)
except RateLimitError:
return await self._extract_anthropic(text)
except Exception as e:
self.error_monitor.log(e)
raise
def _extract_openai(self, text):
# 50+ lines of OpenAI-specific logic
pass
def _extract_anthropic(self, text):
# 50+ lines of Anthropic-specific logic
pass
```
## Enter BAML
What if you could go back to something simple, but keep all the power?
```baml
class Education {
school string
degree string
year int
}
enum SeniorityLevel {
JUNIOR @description("0-2 years of experience")
MID @description("2-5 years of experience")
SENIOR @description("5-10 years of experience")
STAFF @description("10+ years of experience, technical leadership")
}
class Resume {
name string
skills string[]
education Education[]
seniority SeniorityLevel
}
function ExtractResume(resume_text: string) -> Resume {
client GPT4
prompt #"
Extract information from this resume.
Resume:
---
{{ resume_text }}
---
{{ ctx.output_format }}
"#
}
```
Look what you get immediately:
```json
{
"name": "John Doe",
"skills": ["Python", "JavaScript"
// Missing closing bracket!
```
You add retry logic, JSON fixing, error handling:
```python
import re
import time
def extract_resume(text, max_retries=3):
for attempt in range(max_retries):
try:
response = openai.chat.completions.create(...)
content = response.choices[0].message.content
# Try to fix common JSON issues
content = fix_json(content)
data = json.loads(content)
return Resume(**data)
except (json.JSONDecodeError, ValidationError) as e:
if attempt == max_retries - 1:
raise
time.sleep(2 ** attempt) # Exponential backoff
def fix_json(content):
# Remove text before/after JSON
json_match = re.search(r'\{.*\}', content, re.DOTALL)
if json_match:
content = json_match.group(0)
# Fix common issues
content = content.replace(',}', '}')
content = content.replace(',]', ']')
# ... more fixes
return content
```
Your simple extraction function is now 50+ lines of infrastructure code.
## Multi-model chaos
Your company wants to use Claude for some tasks (better reasoning) and GPT-4-mini for others (cost savings):
```python
def extract_resume(text, provider="openai", model="gpt-4o"):
if provider == "openai":
import openai
client = openai.OpenAI()
response = client.chat.completions.create(model=model, ...)
elif provider == "anthropic":
import anthropic
client = anthropic.Anthropic()
# Different API! Need to rewrite everything
response = client.messages.create(model=model, ...)
# ... handle different response formats
```
Each provider has different APIs, different response formats, different capabilities. Your code becomes a mess of if/else statements.
## The prompt mystery
Your extraction fails on certain resumes. You need to debug, but what was actually sent to the LLM?
```python
# What prompt was generated? How many tokens did it use?
# Why did this specific resume fail?
# How do I optimize for cost?
# You can't easily see:
# - The exact prompt that was sent
# - How the schema was formatted
# - Token usage breakdown
# - Why specific fields were missed
```
You start adding logging, token counting, prompt inspection tools...
## Classification gets complex
Now you need to classify seniority levels:
```python
from enum import Enum
class SeniorityLevel(str, Enum):
JUNIOR = "junior"
MID = "mid"
SENIOR = "senior"
STAFF = "staff"
class Resume(BaseModel):
name: str
skills: list[str]
education: list[Education]
seniority: SeniorityLevel
```
But the LLM doesn't know what these levels mean! You update the prompt:
```python
prompt = f"""Extract resume data as JSON:
Seniority levels:
- junior: 0-2 years experience
- mid: 2-5 years experience
- senior: 5-10 years experience
- staff: 10+ years experience
{text}
Return JSON with fields: name, skills, education, seniority..."""
```
Your prompt is getting huge and your business logic is scattered between code and strings.
## Production deployment headaches
In production, you need:
* Retry policies for rate limits
* Fallback models when primary is down
* Cost tracking and optimization
* Error monitoring and alerting
* A/B testing different prompts
Your simple extraction function becomes a complex service:
```python
class ResumeExtractor:
def __init__(self):
self.primary_client = openai.OpenAI()
self.fallback_client = anthropic.Anthropic()
self.token_tracker = TokenTracker()
self.error_monitor = ErrorMonitor()
async def extract_with_fallback(self, text):
try:
return await self._extract_openai(text)
except RateLimitError:
return await self._extract_anthropic(text)
except Exception as e:
self.error_monitor.log(e)
raise
def _extract_openai(self, text):
# 50+ lines of OpenAI-specific logic
pass
def _extract_anthropic(self, text):
# 50+ lines of Anthropic-specific logic
pass
```
## Enter BAML
What if you could go back to something simple, but keep all the power?
```baml
class Education {
school string
degree string
year int
}
enum SeniorityLevel {
JUNIOR @description("0-2 years of experience")
MID @description("2-5 years of experience")
SENIOR @description("5-10 years of experience")
STAFF @description("10+ years of experience, technical leadership")
}
class Resume {
name string
skills string[]
education Education[]
seniority SeniorityLevel
}
function ExtractResume(resume_text: string) -> Resume {
client GPT4
prompt #"
Extract information from this resume.
Resume:
---
{{ resume_text }}
---
{{ ctx.output_format }}
"#
}
```
Look what you get immediately:
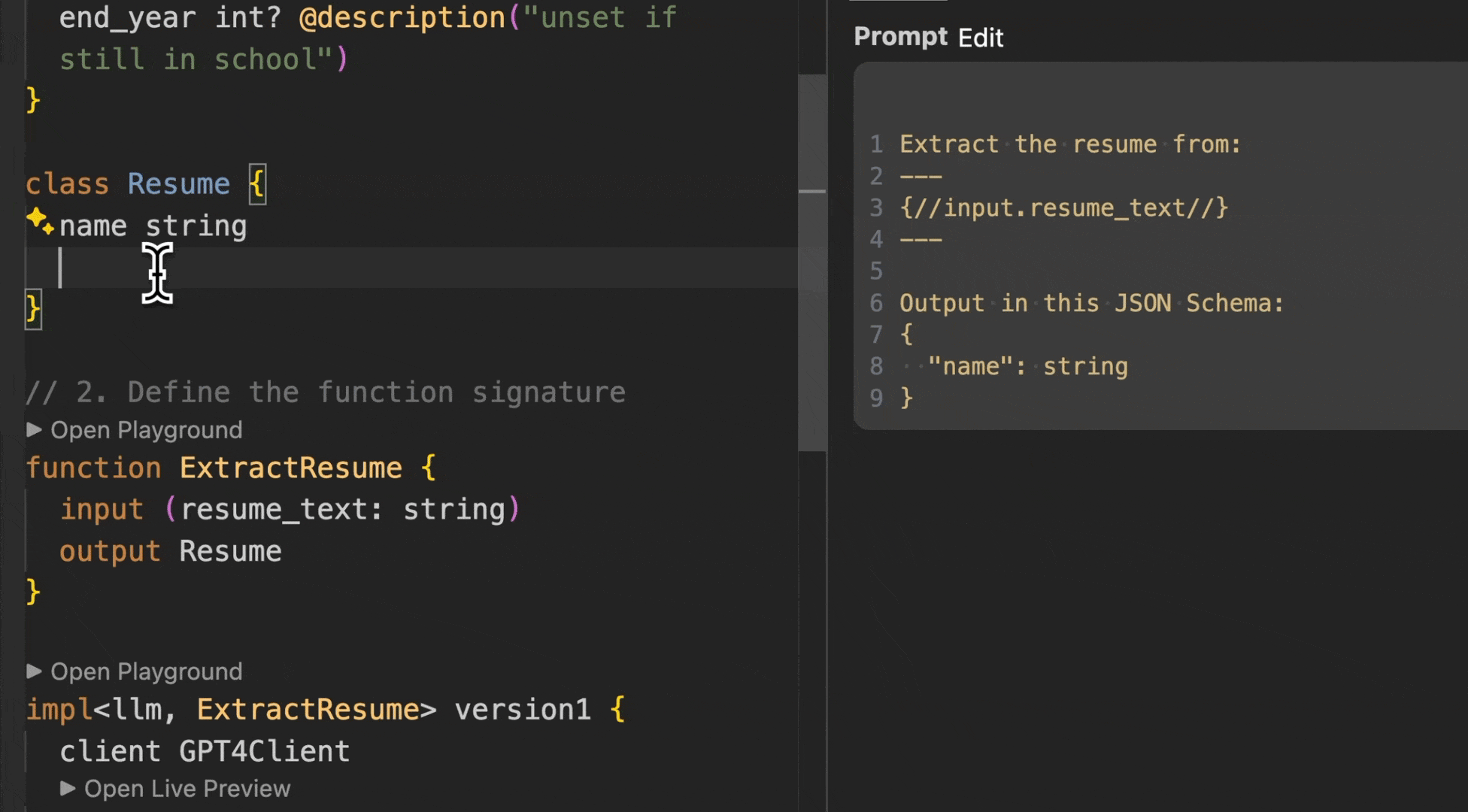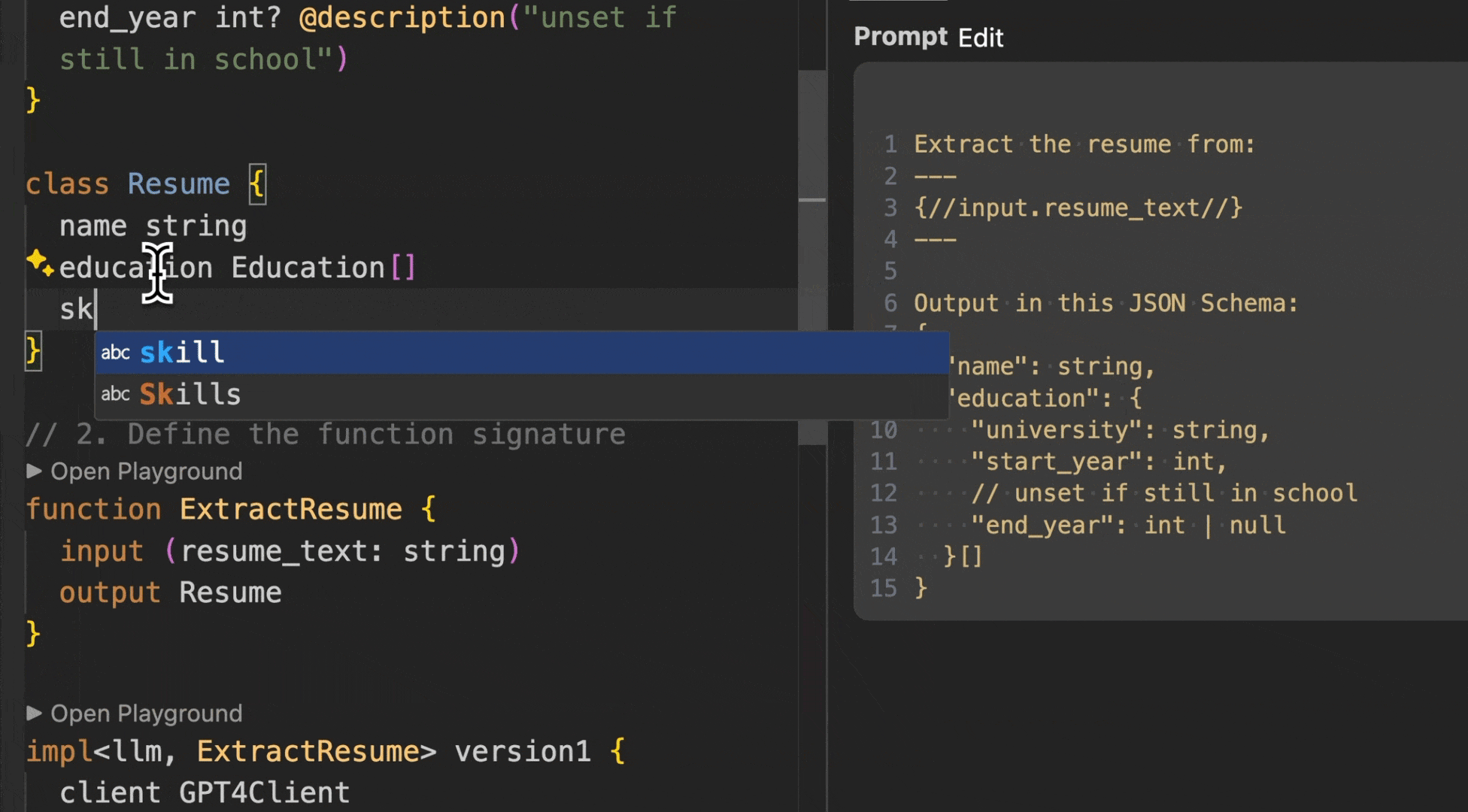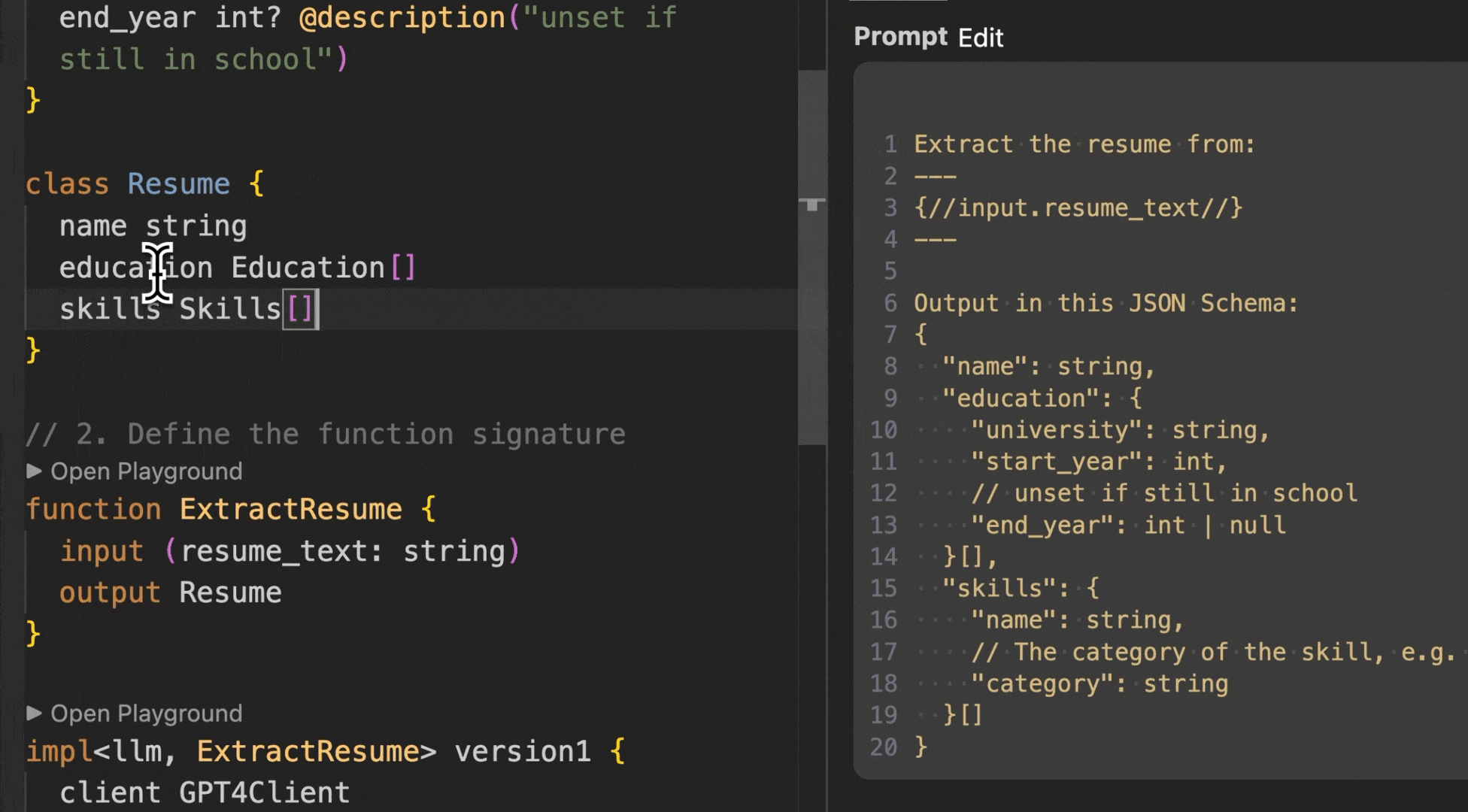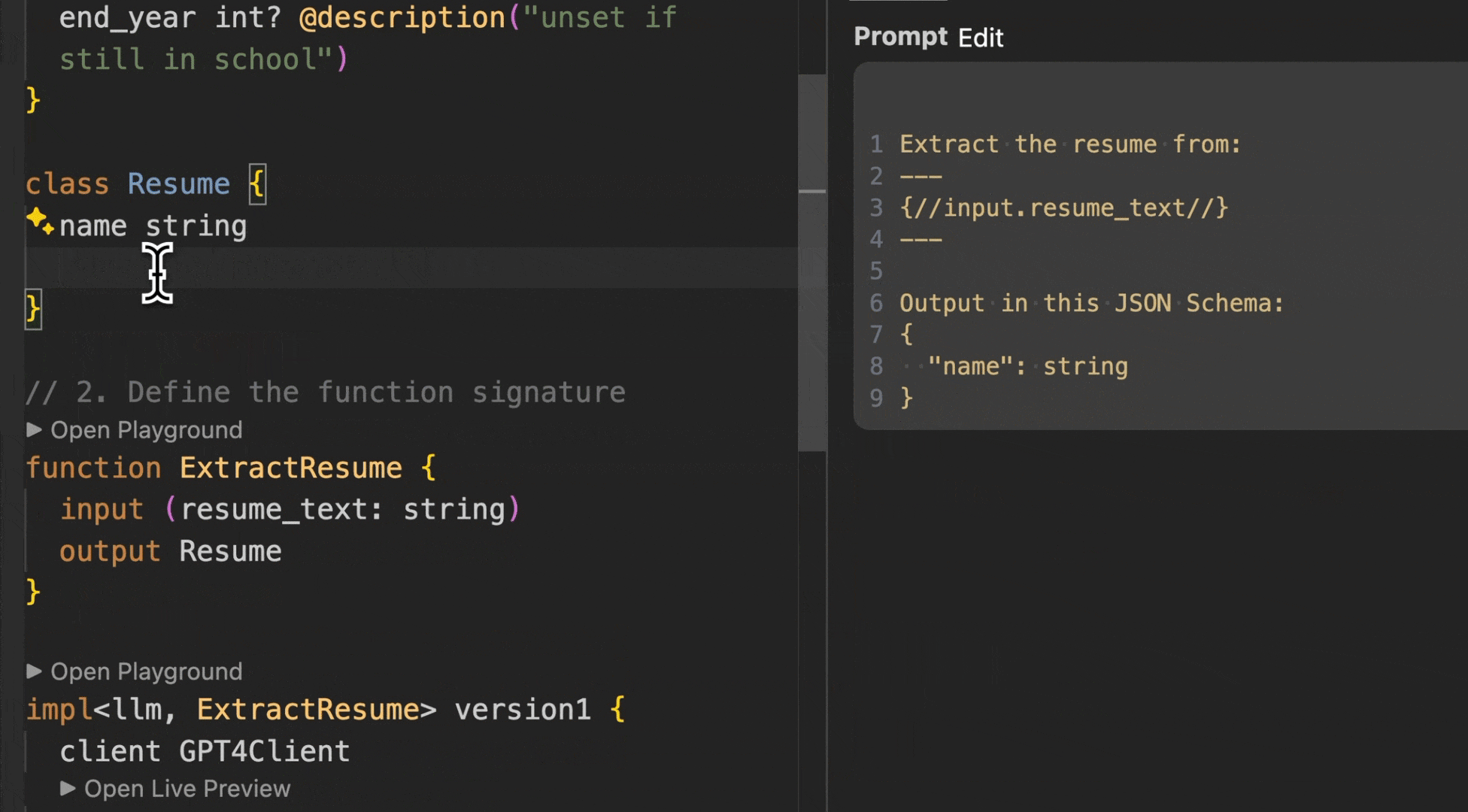
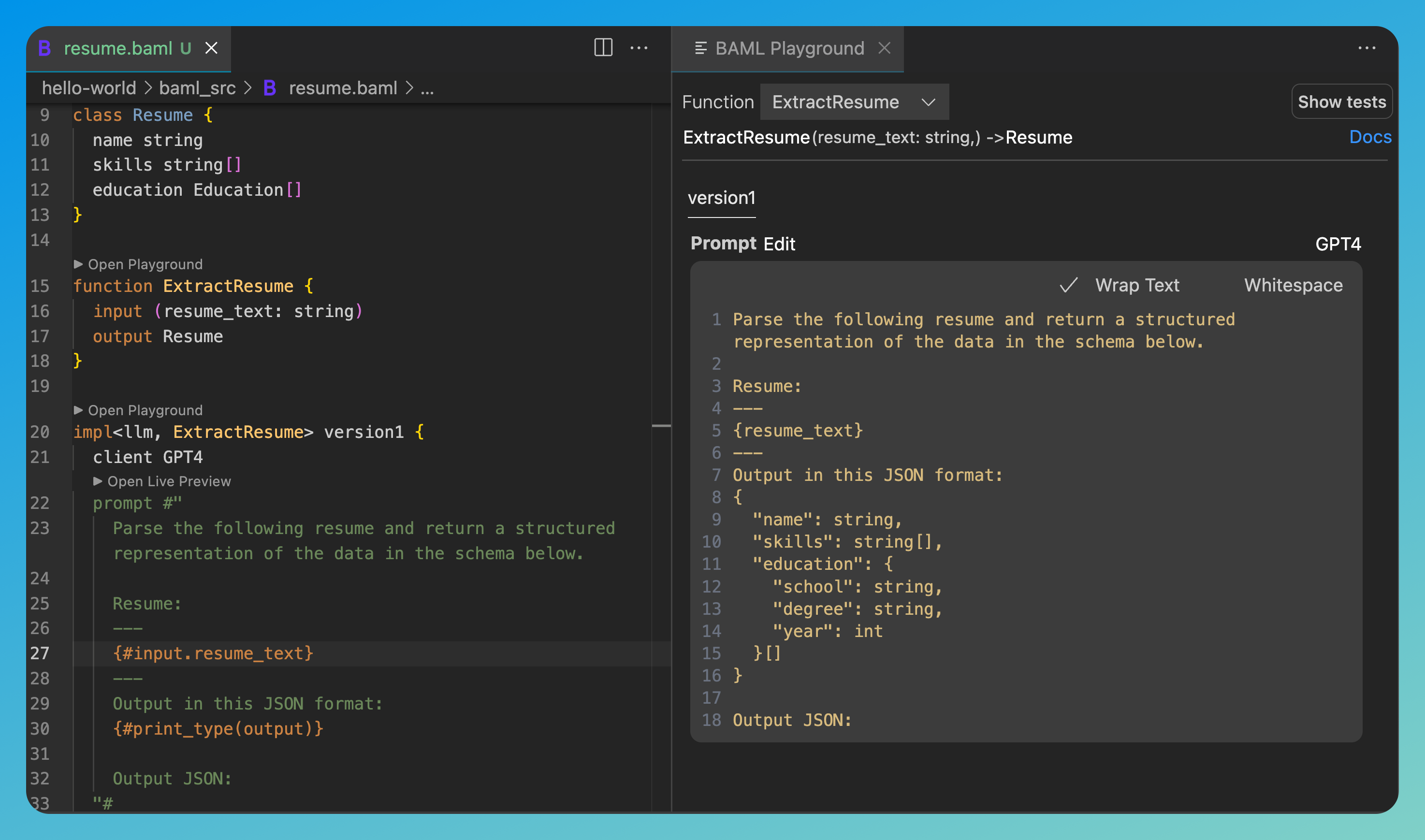 *BAML playground showing successful resume extraction with clear prompts and structured output*
### 1. **Instant Testing**
Test in VSCode playground without API calls or token costs:
*BAML playground showing successful resume extraction with clear prompts and structured output*
### 1. **Instant Testing**
Test in VSCode playground without API calls or token costs:
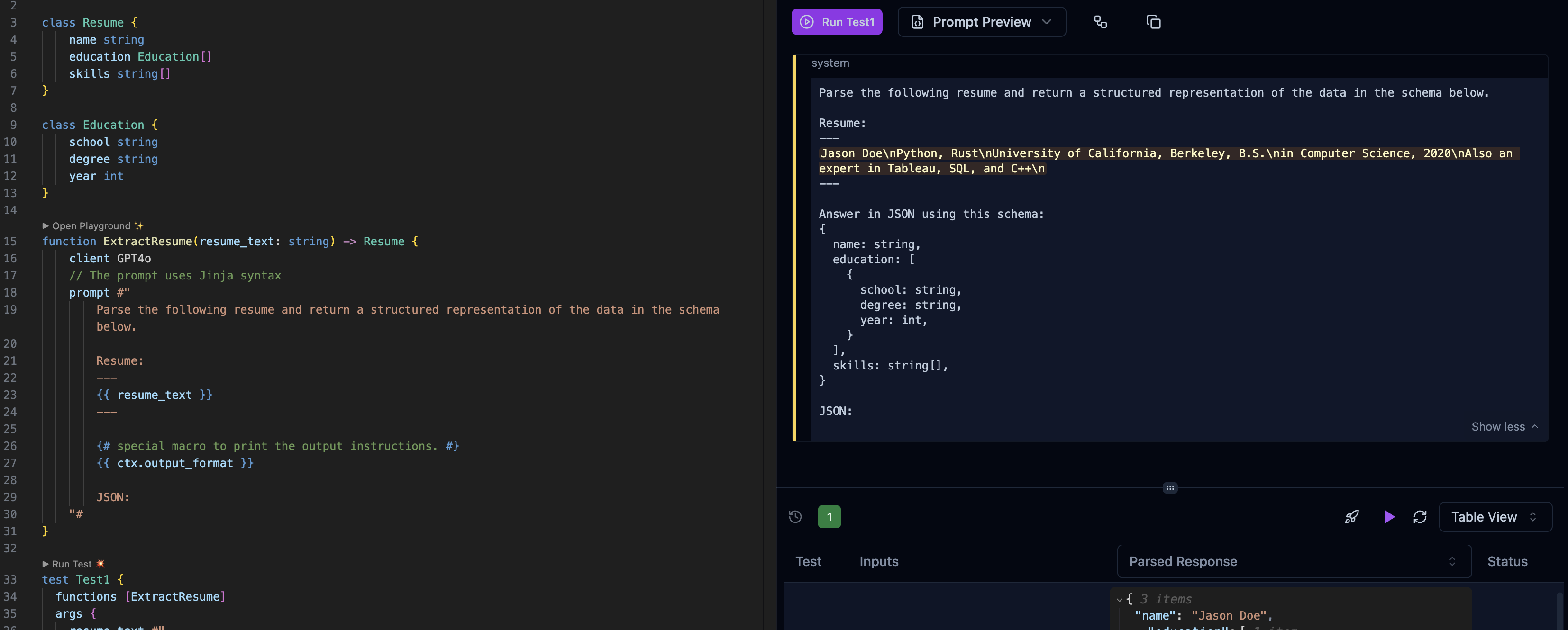 * **See the exact prompt** that will be sent to the LLM
* **Test with real data instantly** - no API calls needed
* **Save test cases** for regression testing
* **Visual prompt preview** shows token usage and formatting
* **See the exact prompt** that will be sent to the LLM
* **Test with real data instantly** - no API calls needed
* **Save test cases** for regression testing
* **Visual prompt preview** shows token usage and formatting
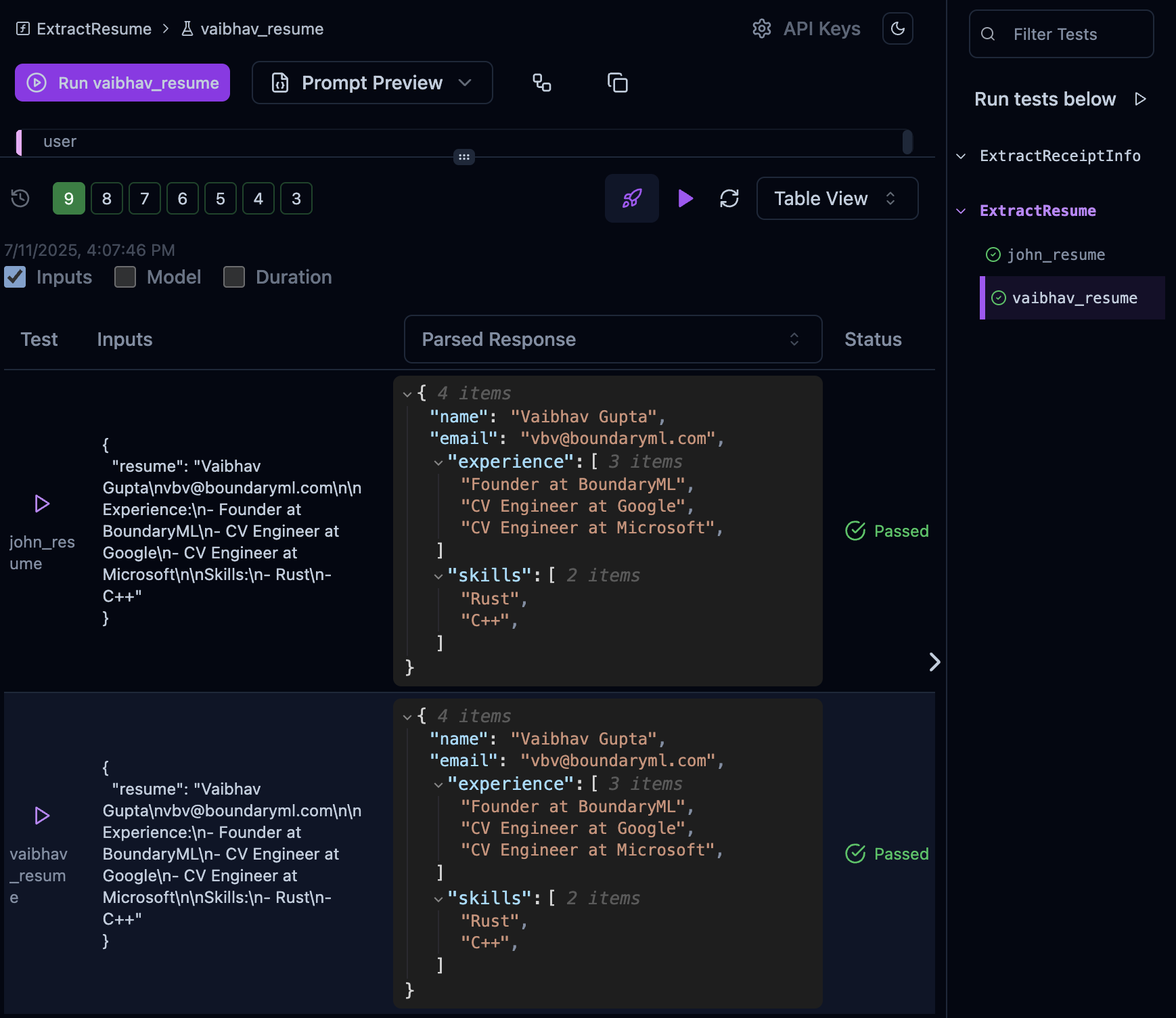 *Build up a library of test cases that run instantly*
### 2. **Multi-Model Made Simple**
```baml
client
*Build up a library of test cases that run instantly*
### 2. **Multi-Model Made Simple**
```baml
client ```python
from baml_client import baml as b
# Fully typed, works in Python, TypeScript, Java, Go
resume = await b.ExtractResume(resume_text)
print(resume.seniority) # Type: SeniorityLevel
```
*BAML generates fully typed clients for all languages automatically*
**See how changes instantly update the prompt:**
```python
from baml_client import baml as b
# Fully typed, works in Python, TypeScript, Java, Go
resume = await b.ExtractResume(resume_text)
print(resume.seniority) # Type: SeniorityLevel
```
*BAML generates fully typed clients for all languages automatically*
**See how changes instantly update the prompt:**
 *Change your types → Prompt automatically updates → See the difference immediately*
### 7. **Advanced Streaming with UI Integration**
BAML's semantic streaming lets you build real UIs with loading bars and type-safe implementations:
```baml
class BlogPost {
title string @stream.done @stream.not_null
content string @stream.with_state
}
```
**What this enables:**
* **Loading bars** - Show progress as structured data streams in
* **Semantic guarantees** - Title only appears when complete, content streams token by token
* **Type-safe streaming** - Full TypeScript/Python types for partial data
* **UI state management** - Know exactly what's loading vs complete
*See semantic streaming in action - structured data streaming with loading states*
## The Bottom Line
**You started with:** A simple LLM call
**You ended up with:** Hundreds of lines of infrastructure code
**With BAML, you get:**
* The simplicity of your first attempt
* All the production features you built manually
* Better reliability than you could build yourself
* 10x faster development iteration
* Full control and transparency
BAML is what LLM development should have been from the start. Ready to see the difference? [Get started with BAML](/guide/installation-language/python).
*Change your types → Prompt automatically updates → See the difference immediately*
### 7. **Advanced Streaming with UI Integration**
BAML's semantic streaming lets you build real UIs with loading bars and type-safe implementations:
```baml
class BlogPost {
title string @stream.done @stream.not_null
content string @stream.with_state
}
```
**What this enables:**
* **Loading bars** - Show progress as structured data streams in
* **Semantic guarantees** - Title only appears when complete, content streams token by token
* **Type-safe streaming** - Full TypeScript/Python types for partial data
* **UI state management** - Know exactly what's loading vs complete
*See semantic streaming in action - structured data streaming with loading states*
## The Bottom Line
**You started with:** A simple LLM call
**You ended up with:** Hundreds of lines of infrastructure code
**With BAML, you get:**
* The simplicity of your first attempt
* All the production features you built manually
* Better reliability than you could build yourself
* 10x faster development iteration
* Full control and transparency
BAML is what LLM development should have been from the start. Ready to see the difference? [Get started with BAML](/guide/installation-language/python).