

Comparing Pydantic
Pydantic is a popular library for data validation in Python used by most — if not all — LLM frameworks, like instructor.
BAML also uses Pydantic. The BAML Rust compiler can generate Pydantic models from your .baml files. But that’s not all the compiler does — it also takes care of fixing common LLM parsing issues, supports more data types, handles retries, and reduces the amount of boilerplate code you have to write.
Let’s dive into how Pydantic is used and its limitations.
Why working with LLMs requires more than just Pydantic
Pydantic can help you get structured output from an LLM easily at first glance:
That’s pretty good, but now we want to add an Education model to the Resume model. We add the following code:
A little ugly, but still readable… But managing all these prompt strings can make your codebase disorganized very quickly.
Then you realize the LLM sometimes outputs some text before giving you the json, like this:
So you add a regex to address that that extracts everything in {}:
Next you realize you actually want an array of Resumes, but you can’t really use List[Resume] because Pydantic and Python don’t work this way, so you have to add another wrapper:
Now you need to change the rest of your code to handle different models. That’s good longterm, but it is now more boilerplate you have to write, test and maintain.
Next, you notice the LLM sometimes outputs a single resume {...}, and sometimes an array [{...}]…
You must now change your parser to handle both cases:
You could retry the call against the LLM to fix the issue, but that will cost you precious seconds and tokens, so handling this corner case manually is the only solution.
A small tangent — JSON schemas vs type definitions
Sidenote: At this point your prompt looks like this:
and sometimes even GPT-4 outputs incorrect stuff like this, even though it’s technically correct JSON (OpenAI’s “JSON mode” will still break you)
(this is an actual result from GPT-4 before some more prompt engineering)
when all you really want is a prompt that looks like the one below — with way less tokens (and less likelihood of confusion). :
Ahh, much better. That’s 80% less tokens with a simpler prompt, for the same results. (See also Microsoft’s TypeChat which uses a similar schema format using typescript types)
But we digress, let’s get back to the point. You can see how this can get out of hand quickly, and how Pydantic wasn’t really made with LLMs in mind. We haven’t gotten around to adding resilience like retries, or falling back to a different model in the event of an outage. There’s still a lot of wrapper code to write.
Pydantic and Enums
There are other core limitations. Say you want to do a classification task using Pydantic. An Enum is a great fit for modelling this.
Assume this is our prompt:
Since we have descriptions, we need to generate a custom enum we can use to build the prompt:
We add a class method to load the right enum from the LLM output string:
Update the prompt to use the enum descriptions:
And then we use it in our AI function:
What gets hairy is if you want to change your types.
- What if you want the LLM to return an object instead? You have to change your enum, your prompt, AND your parser.
- What if you want to handle cases where the LLM outputs “Real Estate” or “real estate”?
- What if you want to save the enum information in a database?
str(category)will saveFinancialCategory.healthcareinto your DB, but your parser only recognizes “Healthcare”, so you’ll need more boilerplate if you ever want to programmatically analyze your data.
Alternatives
There are libraries like instructor do provide a great amount of boilerplate but you’re still:
- Using prompts that you cannot control. E.g. a commit may change your results underneath you.
- Using more tokens than you may need to to declare schemas (higher costs and latencies)
- There are no included testing capabilities.. Developers have to copy-paste JSON blobs everywhere, potentially between their IDEs and other websites. Existing LLM Playgrounds were not made with structured data in mind.
- Lack of observability. No automatic tracing of requests.
Enter BAML
The Boundary toolkit helps you iterate seamlessly compared to Pydantic.
Here’s all the BAML code you need to solve the Extract Resume problem from earlier (VSCode prompt preview is shown on the right):
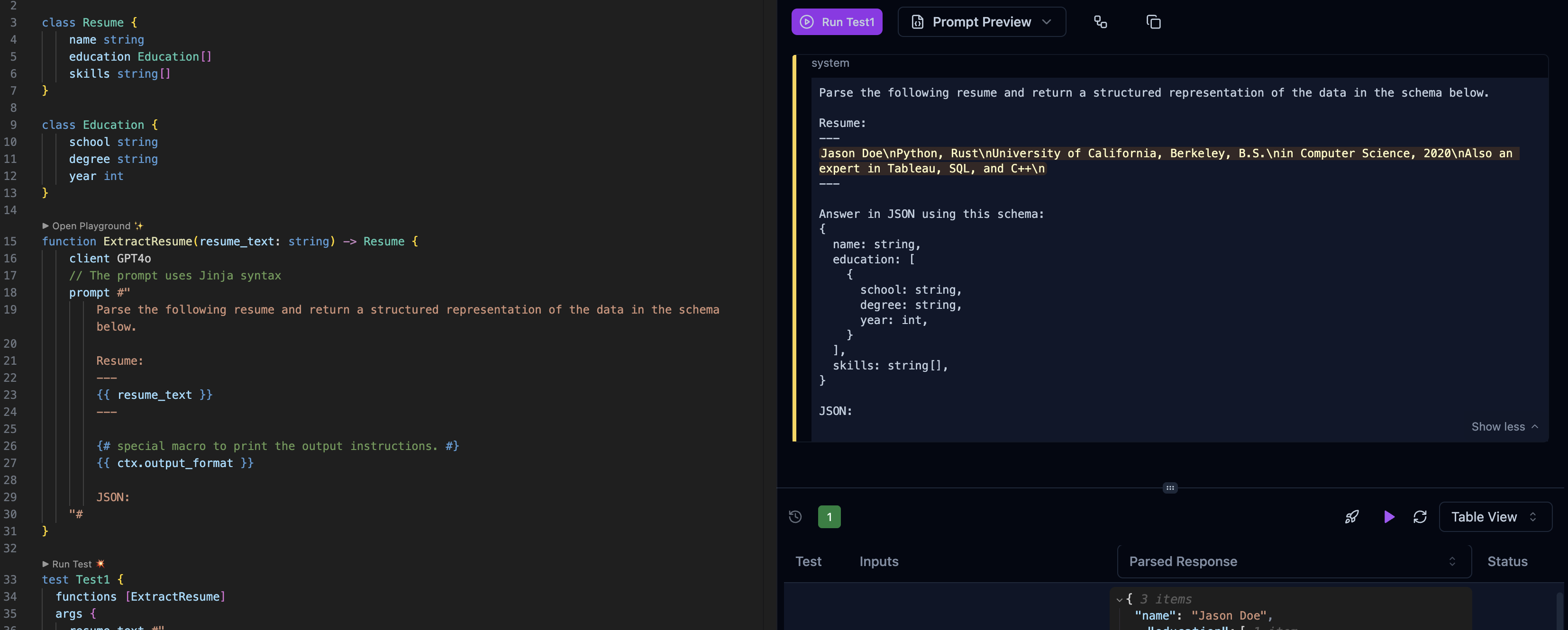
Here we use a “GPT4” client, but you can use any model. See client docs
The BAML compiler generates a python client that imports and calls the function:
That’s it! No need to write any more code. Since the compiler knows what your function signature is we literally generate a custom deserializer for your own unique usecase that just works.
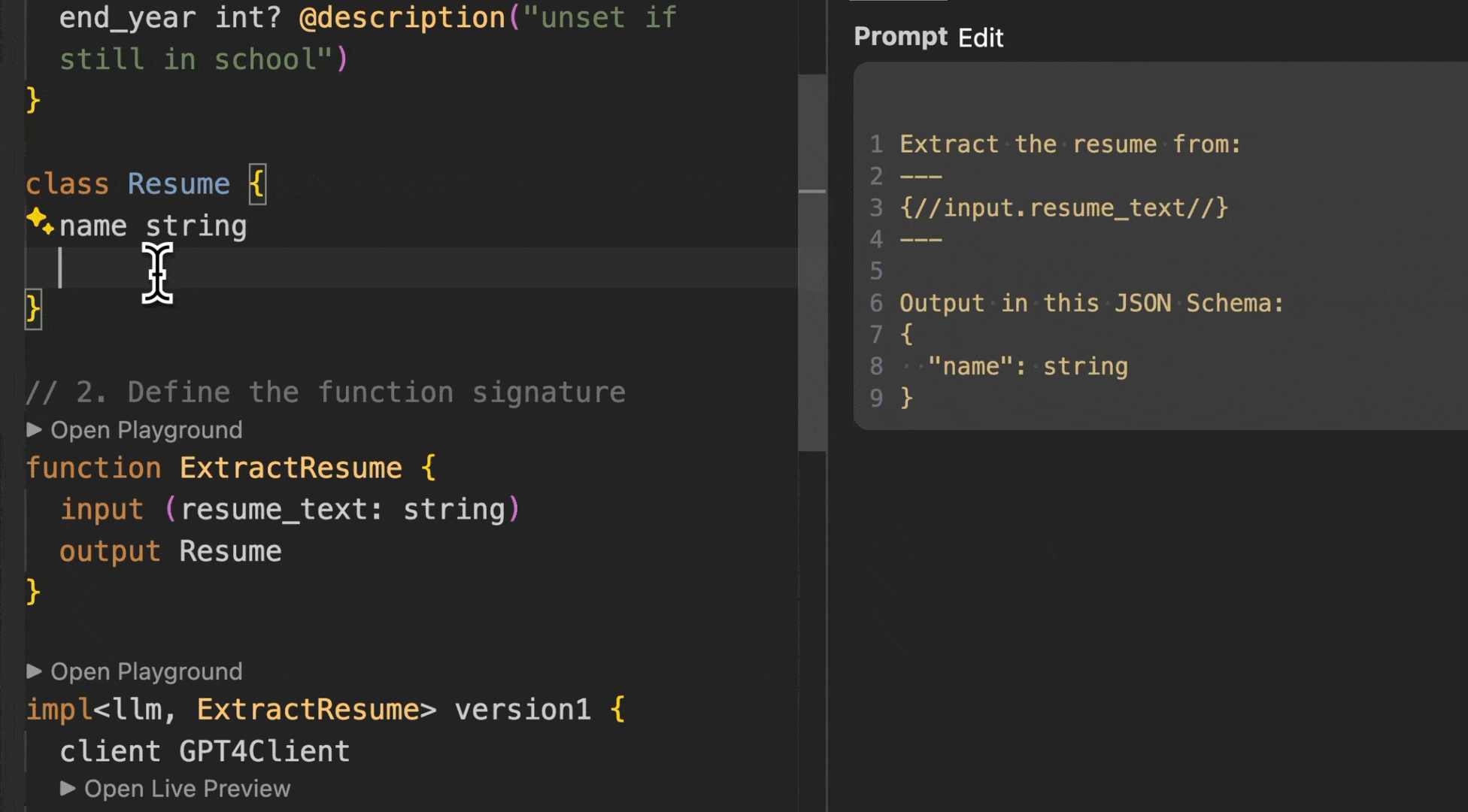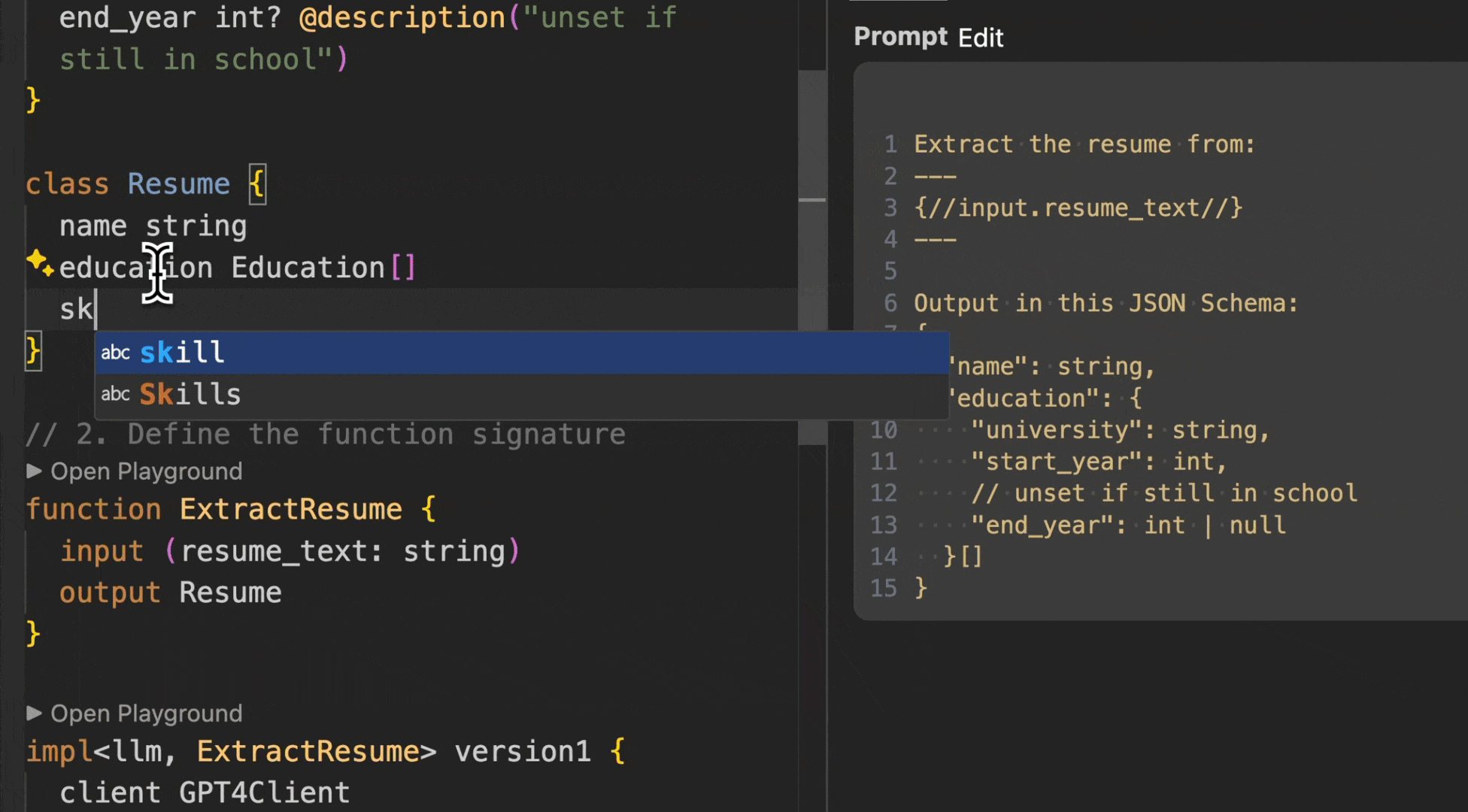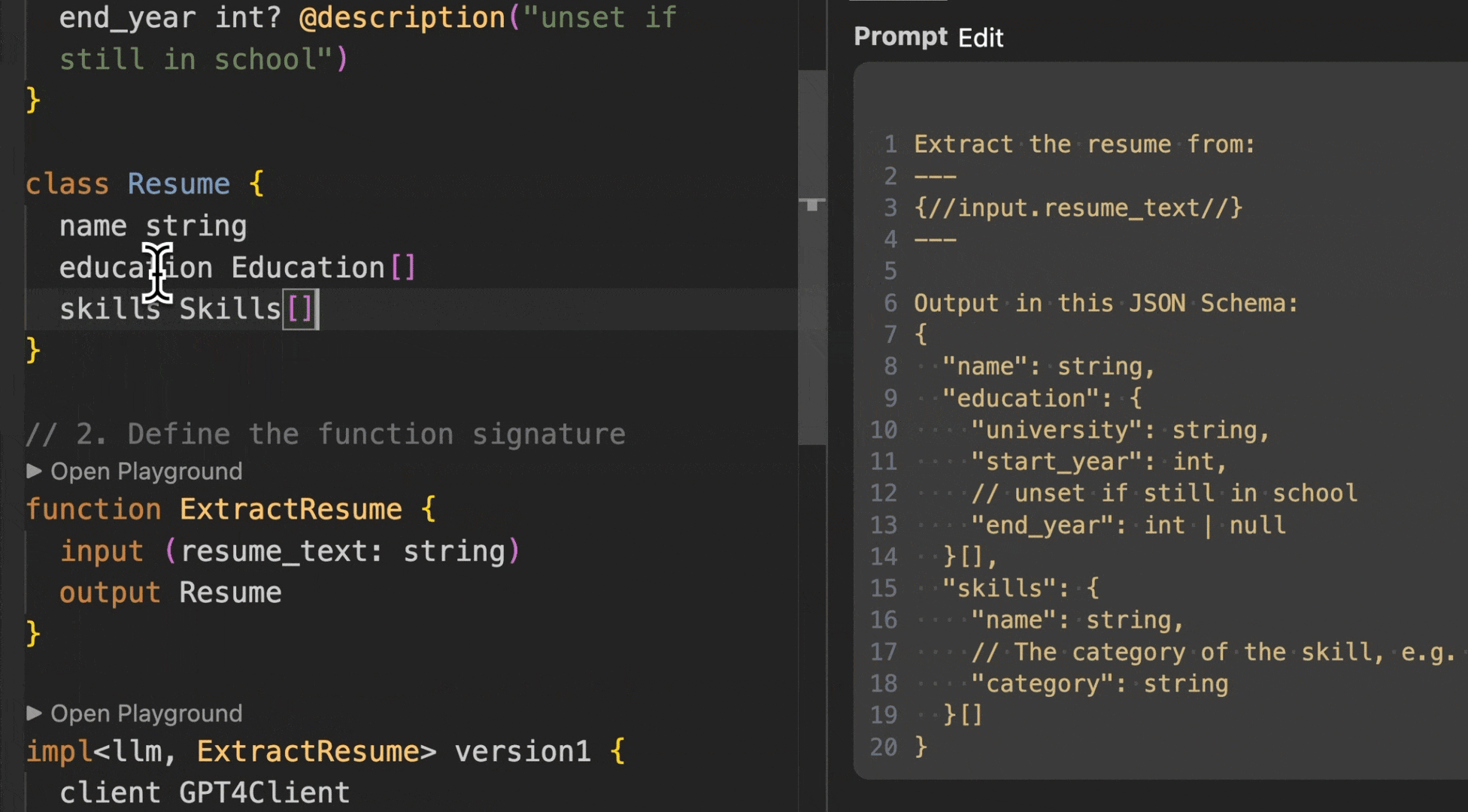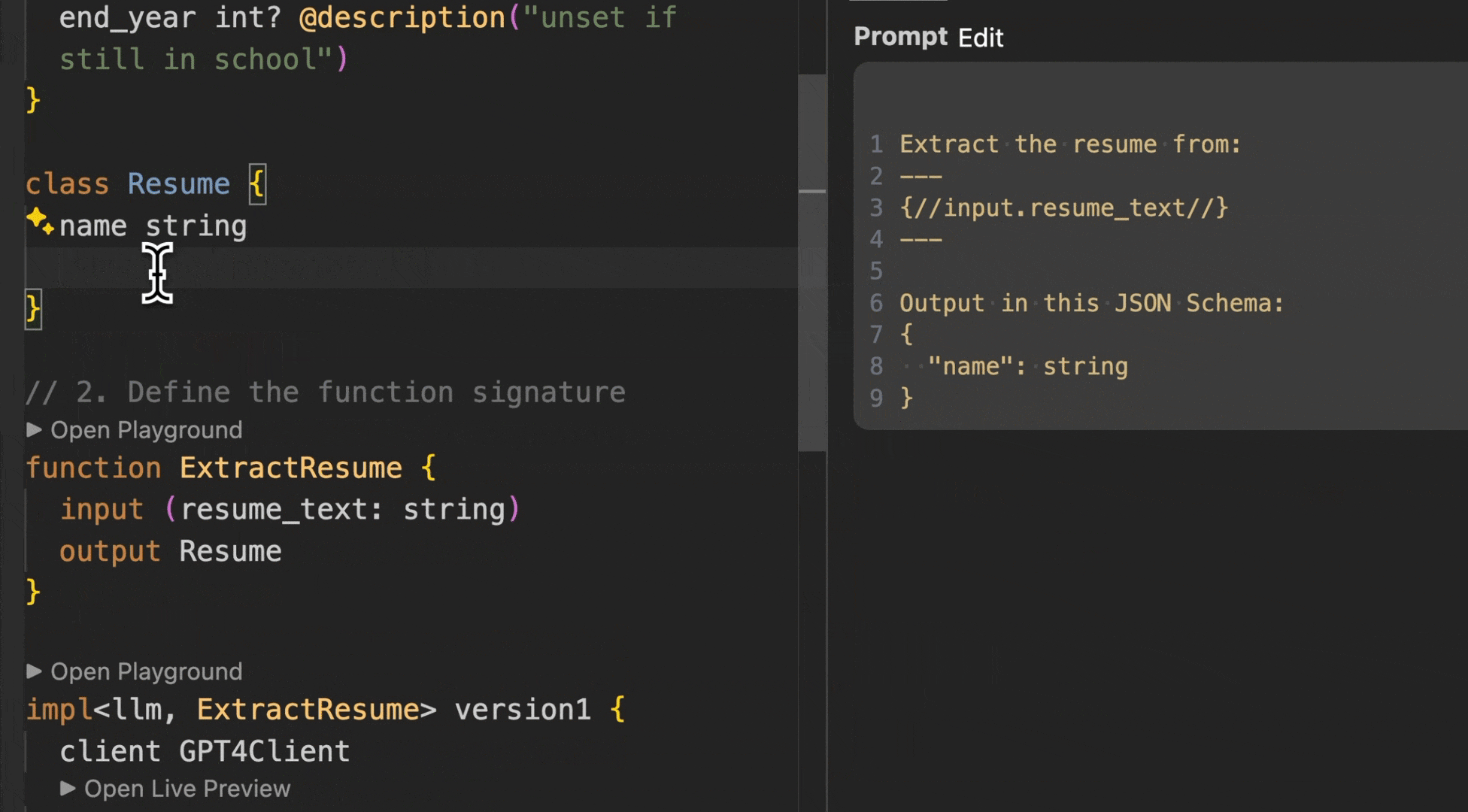
Converting the Resume into an array of resumes requires a single line change in BAML (vs having to create array wrapper classes and parsing logic).
In this image we change the types and BAML automatically updates the prompt, parser, and the Python types you get back.
Adding retries or resilience requires just a couple of modifications. And best of all, you can test things instantly, without leaving your VSCode.
The bottom line
Pydantic is excellent for data validation, but LLM applications need more than validation - they need a complete structured extraction solution.
BAML’s advantages over Pydantic:
- No boilerplate - BAML generates all parsing, retry, and error handling code
- Visual development - See prompts and test instantly in VSCode
- Better prompts - Optimized schema format uses 80% fewer tokens
- Schema-Aligned Parsing - Handles malformed JSON and edge cases automatically
- Multi-model support - Works with any LLM provider, not just OpenAI
- Type safety across languages - Generated clients for Python, TypeScript, Java, Go
- Built-in resilience - Retries, fallbacks, and smart error recovery
What you get with BAML that Pydantic can’t provide:
- Instant testing - No API calls or token costs during development
- Prompt optimization - See exactly what’s sent and optimize token usage
- Production features - Automatic retries, model fallbacks, streaming support
- Better debugging - Know exactly why extraction failed
- Future-proof - Never get locked into one model or provider
Why this matters for your team:
- 10x faster iteration - Test prompts instantly without running Python code
- Better reliability - Handle edge cases and malformed outputs automatically
- Cost optimization - Reduce token usage with optimized schema formats
- Model flexibility - Switch between GPT, Claude, open-source models seamlessly
We built BAML because writing a Python library wasn’t powerful enough to solve the real challenges of LLM structured extraction.
Conclusion
Get started today with Python, TypeScript, Go, Ruby or other languages.
Our mission is to make the best developer experience for AI engineers working with LLMs. Contact us at founders@boundaryml.com or Join us on Discord to stay in touch with the community and influence the roadmap.